面试题--Hibernate--小米归纳
大纲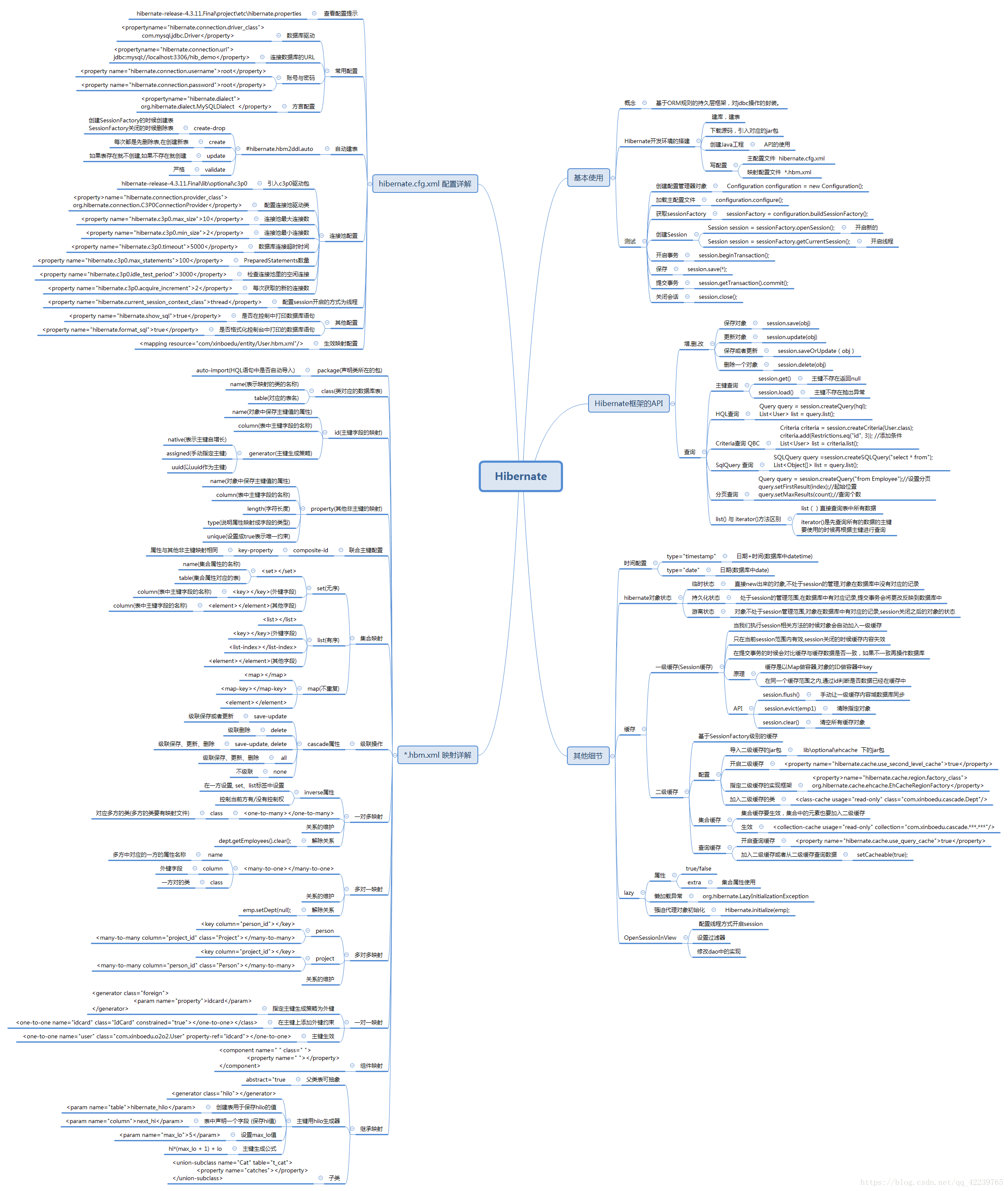
未归类
Hibernate是如何延迟加载(懒加载)?
通过设置属性 lazy 进行设置是否需要懒加载
当Hibernate在查询数据的时候,数据并没有存在与内存中,当程序真正对数据的操作时,对象才存在与内存中,就实现了延迟加载,他节省了服务器的内存开销,从而提高了服务器的性能。
Hibernate中怎样实现类之间的关系?(如:一对多、多对多的关系)
它们通过配置文件中的 many-to-one 、one-to-many 、many-to-many 来实现类之间的关联关系的。
hibernate的三种状态之间如何转换
Hibernate中对象的状态:
临时/瞬时状态
持久化状态
游离状态
临时/瞬时状态
当我们直接new出来的对象就是临时/瞬时状态的..
- 该对象还没有被持久化【没有保存在数据库中】
- 不受Session的管理
持久化状态
当保存在数据库中的对象就是持久化状态了
- 当调用session的save/saveOrUpdate/get/load/list等方法的- 时候,对象就是持久化状态
- 在数据库有对应的数据
- 受Session的管理
- 当对对象属性进行更改的时候,会反映到数据库中!
游离状态
当Session关闭了以后,持久化的对象就变成了游离状态了…
- 不处于session的管理
- 数据库中有对应的记录
new出来的对象是瞬时状态 -> 保存到数据库中(受Session管理)就是持久化状态 -> 将session close掉就是游离状态
比较hibernate的三种检索策略优缺点
| 策略 | 优点 | 缺点 | 配置方法 |
|---|---|---|---|
| 立即检索 | 对应用程序完全透明,不管对象处于持久化状态,还是游离状态,应用程序都可以方便的从一个对象导航到与它关联的对象; |
|
lazy=false; |
| 延迟检索 | 由应用程序决定需要加载哪些对象,可以避免可执行多余的select语句,以及避免加载应用程序不需要访问的对象。因此能提高检索性能,并且能节省内存空间; | 应用程序如果希望访问游离状态代理类实例,必须保证他在持久化状态时已经被初始化; | lazy=true; |
| 迫切左外连接检索 |
|
|
fetch=“join” |
hibernate都支持哪些缓存策略
usage的属性有4种:
- 放入二级缓存的对象,只读(Read-only);
- 非严格的读写(Nonstrict read/write)
- 读写; 放入二级缓存的对象可以读、写(Read/write);
- 基于事务的策略(Transactional)
hibernate里面的sorted collection 和ordered collection有什么区别
sorted collection
是在内存中通过Java比较器进行排序的
ordered collection
是在数据库中通过order by进行排序的
对于比较大的数据集,为了避免在内存中对它们进行排序而出现 Java中的OutOfMemoryError,最好使用ordered collection。
说下Hibernate的缓存机制
一级缓存:
- Hibenate中一级缓存,也叫做session的缓存,它可以在session范围内减少数据库的访问次数! 只在session范围有效! Session关闭,一级缓存失效!
- 只要是持久化对象状态的,都受Session管理,也就是说,都会在Session缓存中!
- Session的缓存由hibernate维护,用户不能操作缓存内容; 如果想操作缓存内容,必须通过hibernate提供的evit/clear方法操作。
二级缓存:
- 二级缓存是基于应用程序的缓存,所有的Session都可以使用
- Hibernate提供的二级缓存有默认的实现,且是一种可插配的缓存框架!如果用户想用二级缓存,只需要在hibernate.cfg.xml中配置即可; 不想用,直接移除,不影响代码。
- 如果用户觉得hibernate提供的框架框架不好用,自己可以换其他的缓存框架或自己实现缓存框架都可以。
- Hibernate二级缓存:存储的是常用的类
Hibernate的查询方式有几种
- 对象导航查询(objectcomposition)
- HQL查询
- 属性查询
- 参数查询、命名参数查询
- 关联查询
- 分页查询
- 统计函数
- Criteria 查询
- SQLQuery本地SQL查询
如何优化Hibernate?
- 数据库设计调整
- HQL优化
- API的正确使用(如根据不同的业务类型选用不同的集合及查询API)
- 主配置参数(日志,查询缓存,fetch_size, batch_size等)
- 映射文件优化(ID生成策略,二级缓存,延迟加载,关联优化)
- 一级缓存的管理
- 针对二级缓存,还有许多特有的策略
详情可参考资料:
https://www.cnblogs.com/xhj123/p/6106088.html
谈谈Hibernate中inverse的作用
inverse属性默认是false,就是说关系的两端都来维护关系。
- 比如Student和Teacher是多对多关系,用一个中间表TeacherStudent维护。Gp)
- 如果Student这边inverse=”true”, 那么关系由另一端Teacher维护,就是说当插入Student时,不会操作TeacherStudent表(中间表)。只有Teacher插入或删除时才会触发对中间表的操作。所以两边都inverse=”true”是不对的,会导致任何操作都不触发对中间表的影响;当两边都inverse=”false”或默认时,会导致在中间表中插入两次关系。
如果表之间的关联关系是“一对多”的话,那么inverse只能在“一”的一方来配置!
详情可参考:
https://zhongfucheng.bitcron.com/post/hibernate/hibernate-inversehe-cascadeshu-xing-zhi-shi-yao-dian
JDBC hibernate 和 ibatis 的区别
- jdbc:手动
- 手动写sql
- delete、insert、update要将对象的值一个一个取出传到sql中,不能直接传入一个对象。
- select:返回的是一个resultset,要从ResultSet中一行一行、一个字段一个字段的取出,然后封装到一个对象中,不直接返回一个对象。
- ibatis的特点:半自动化
- sql要手动写
- delete、insert、update:直接传入一个对象
- select:直接返回一个对象
- hibernate:全自动
- 不写sql,自动封装
- delete、insert、update:直接传入一个对象
- select:直接返回一个对象
在数据库中条件查询速度很慢的时候,如何优化?
- 建索引
- 减少表之间的关联
- 优化sql,尽量让sql很快定位数据,不要让sql做全表查询,应该走索引,把数据量大的表排在前面
- 简化查询字段,没用的字段不要,已经对返回结果的控制,尽量返回少量数据
什么是SessionFactory,她是线程安全么
SessionFactory 是Hibrenate单例数据存储和线程安全的,以至于可以多线程同时访问。一个SessionFactory 在启动的时候只能建立一次。SessionFactory应该包装各种单例以至于它能很简单的在一个应用代码中储存.
get和load区别
- get如果没有找到会返回null, load如果没有找到会抛出异常。
- get会先查一级缓存, 再查二级缓存,然后查数据库;load会先查一级缓存,如果没有找到,就创建代理对象, 等需要的时候去查询二级缓存和数据库。
主键生成 策略有哪些
主键的自动生成策略
- identity 自增长(mysql,db2)
- sequence 自增长(序列), oracle中自增长是以序列方法实现**
- native 自增长【会根据底层数据库自增长的方式选择identity或sequence】
- 如果是mysql数据库, 采用的自增长方式是identity
- 如果是oracle数据库, 使用sequence序列的方式实现自增长
- increment 自增长(会有并发访问的问题,一般在服务器集群环境使用会存在问题。)
- assigned 指定主键生成策略为手动指定主键的值
- uuid 指定主键生成策略为UUID生成的值
- foreign(外键的方式)
Hibernate的五个核心接口
- Configuration 接口:配置Hibernate,根据其启动hibernate,创建 SessionFactory 对象;
- SessionFactory 接口:初始化Hibernate,充当数据存储源的代理,创建 session 对象,sessionFactory 是线程安全的,意味着它的同一个实例可以被应 用的多个线程共享,是重量级、二级缓存;
- Session 接口:负责保存、更新、删除、加载和查询对象,是线程不安全的, 避免多个线程共享同一个session,是轻量级、一级缓存;
- Transaction 接口:管理事务;
- Query 和Criteria 接口:执行数据库的查询。